Scale iOS Live Activities - APN Optimizations

JioCinema used live activities to stream cricket scores. Learn how we optimised APN latencies to minimise latencies to provide real time cricket score updates to our customers.Through a series of optimisations, we've achieved a success rate of over 99.99% in our communications with APNs.
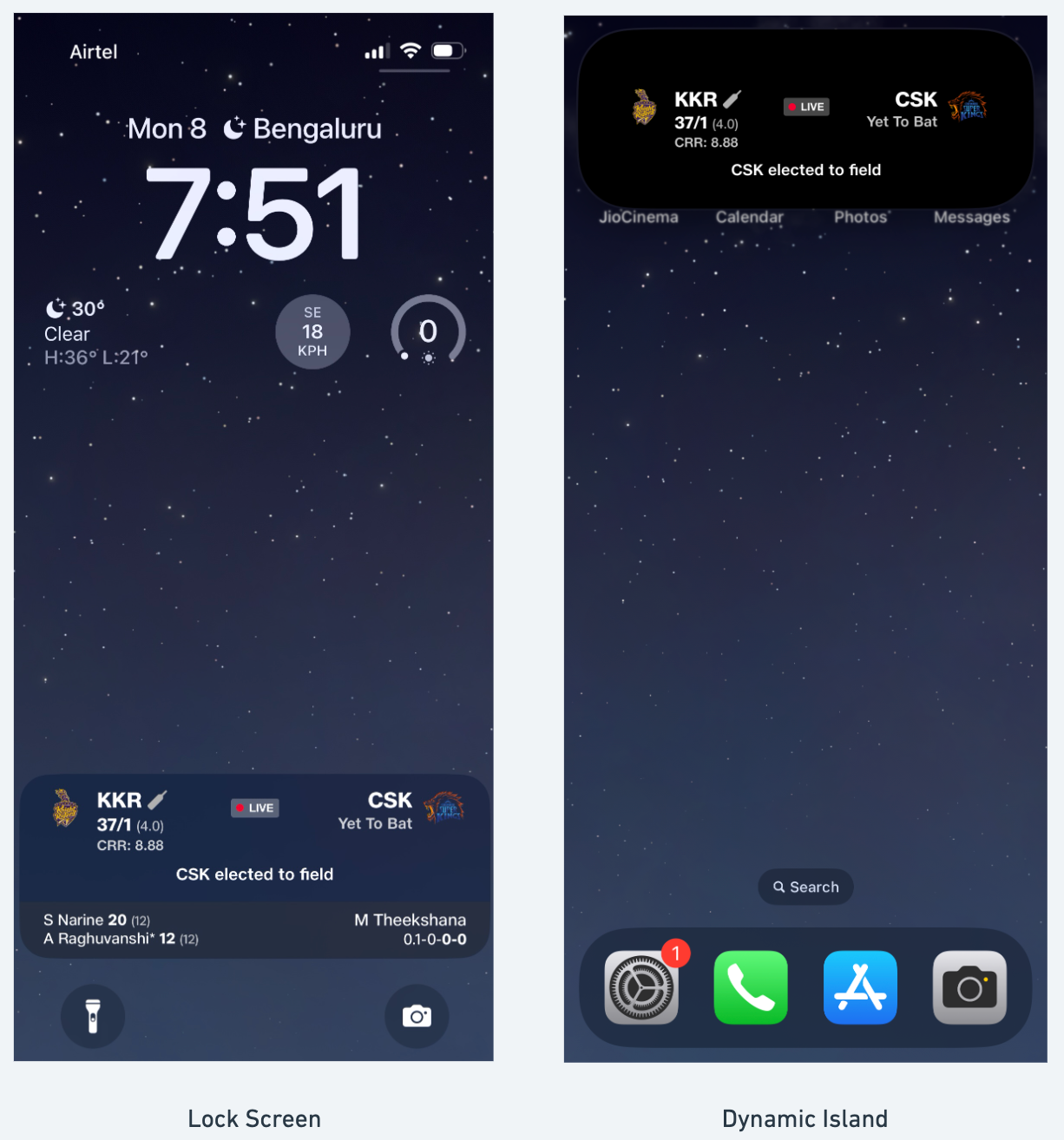
At JioCinema, for TATA IPL 2024, we introduced a new way for our customers to get score updates for a LIVE cricket match. Live Activity feature on iOS devices enables customers to receive score updates during live Cricket matches, even when not actively streaming the game. Our feature smoothly integrates into both the Lock Screen and the Dynamic Island, delivering real-time score updates.
Okay, what’s all the fuss about?
In the iOS ecosystem, unlike the sticky notifications in the Android realm, the Live Activity feature faces distinctive challenges. It inherently lacks the ability to autonomously make network calls or periodically update score data due to limitations within the iOS operating system.
Within iOS, the Apple Push Notification service (APNs) serves as the conduit for updates to the Live Activity feature. Developers are tasked with setting up a backend server, responsible for monitoring live events, receiving device push tokens from customers, and relaying updates to APNs.
With the immense popularity of TATA IPL matches, our iOS customer base swells into the millions, all eager for score updates on their iOS devices. As a result, we dispatch approximately 8-9 million updates per minute to APNs at peak. Managing this scale requires careful calibration of both Computing and I/O resources. Through a series of optimisations, we've achieved a success rate of over 99.99% in our communications with APNs.
In this blog, we explore the various approaches we've taken to facilitate this seamless communication between our backend servers and APNs, and will discuss the strategies that have propelled us to such remarkable numbers.
The Live Activity Loop
When customers opt to subscribe to score updates for an ongoing Cricket match, device asks the Apple Push Notification service (APNs) for a unique push token. Customers then share this token with our servers. Simultaneously, the Live Activity widget appears on their lock screens.
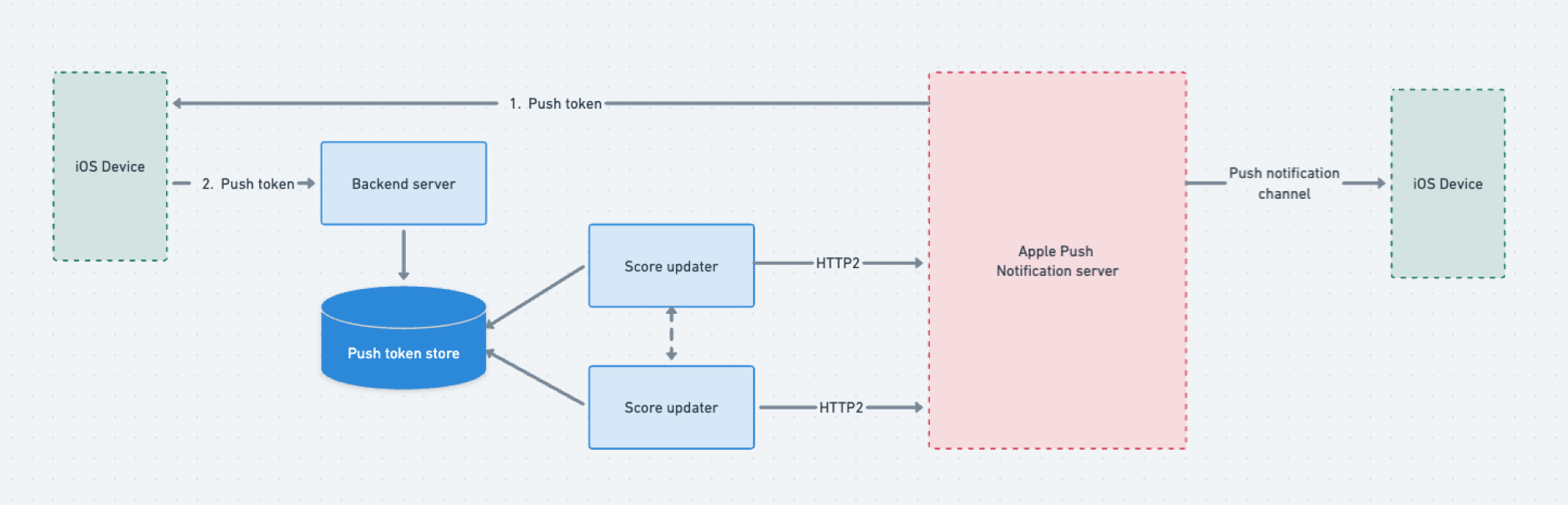
On our end, we store these push tokens in a database. Each Score Update server manages a pool of push tokens and is responsible for sending real-time scores to customers via APNs.
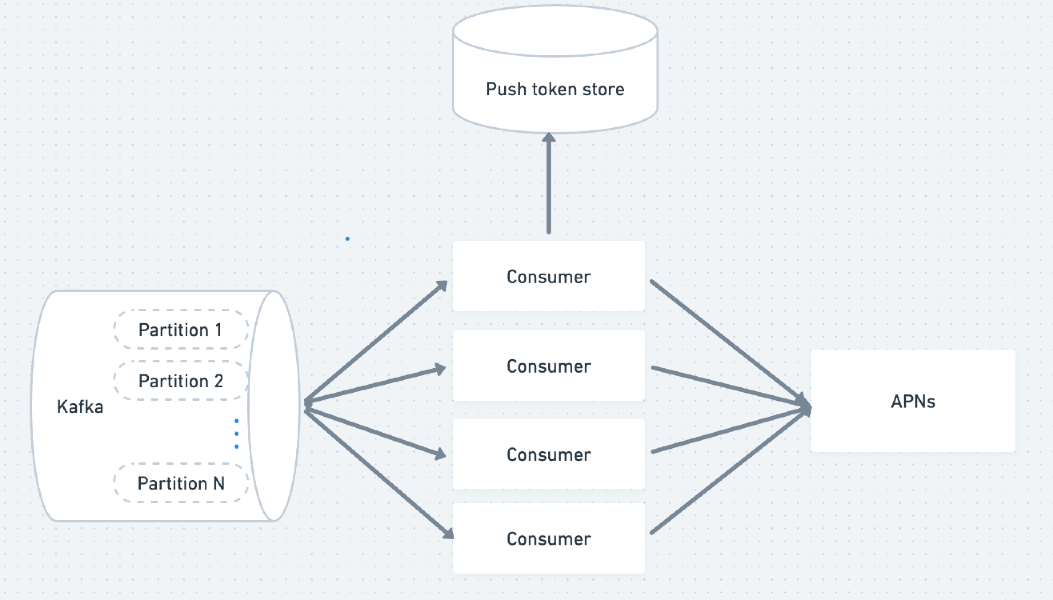
APNs requires us to communicate with them over HTTP2, along with the corresponding push token and the payload. Subsequently, APNs identifies the customer based on the push token and sends the score update through the payload.
This process repeats until the conclusion of the cricket match.
It works, but its slow
With the surge in demand during events like TATA IPL 2024, our backend servers written in Go are tasked with dispatching approximately 8,000 requests in a burst to APNs. However in the initial versions, we encountered significant challenges with processing latencies, experiencing timeouts and failing to meet our service level objectives (SLOs) even when handling just a fraction of target load, with latencies reaching up to 20 seconds.
To address these issues, we embarked on a journey of refinement, trying to enhance the following capabilities -
- Handling millions of requests to APNs concurrently
- Handling APNs high response latency & request timeouts
Increasing APN's Throughput
Sending APNS requests in batches using concurrent go routines
In our initial approach, we employed concurrent Go routines to send requests to APNs in batches of 1000 or 2000 requests. We utilised WaitGroup to ensure that each batch of Go routines completed execution before initiating the next batch. However, this method posed challenges.
For instance, we encountered delays as we had to wait for all Go routines to finish before proceeding with further requests. Even if just one Go routine experienced delays, it hindered the progress of subsequent batches. This increased our total processing latencies significantly for a batch (reaching upto 40 secs).
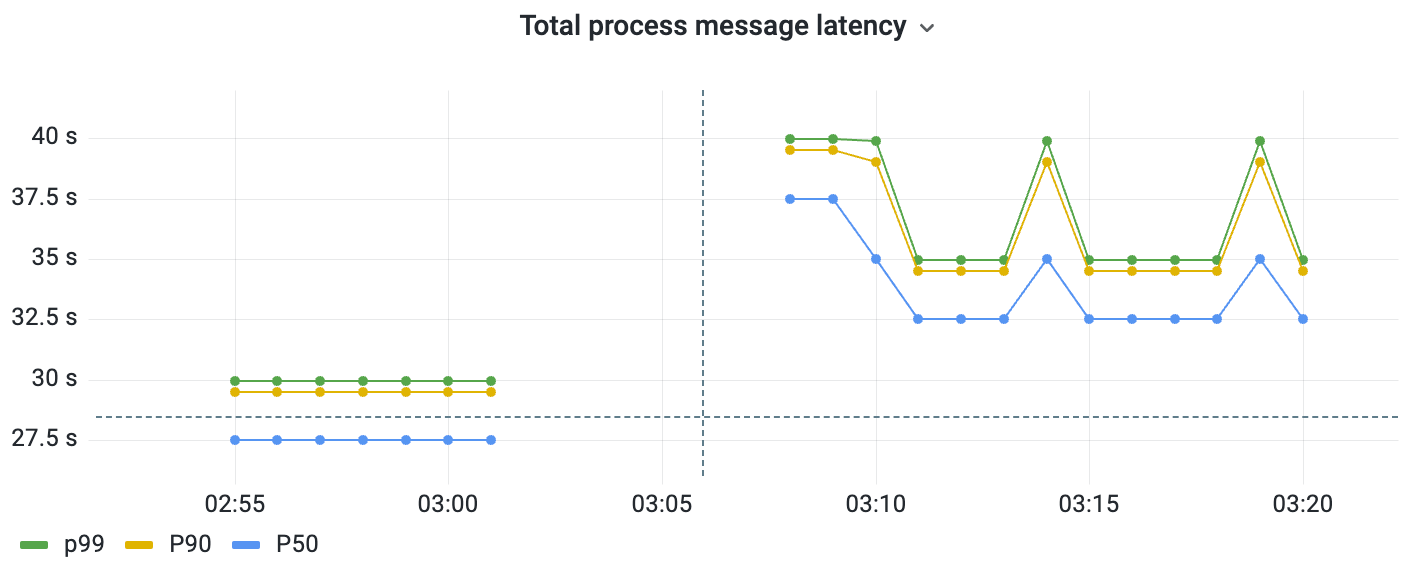
And opting to remove the WaitGroup and allowing unrestricted execution of Go routines proved to be detrimental, as it posed the imminent risk of overwhelming the system, particularly during high-scale matches.
Adding buffered channel to process APNS requests
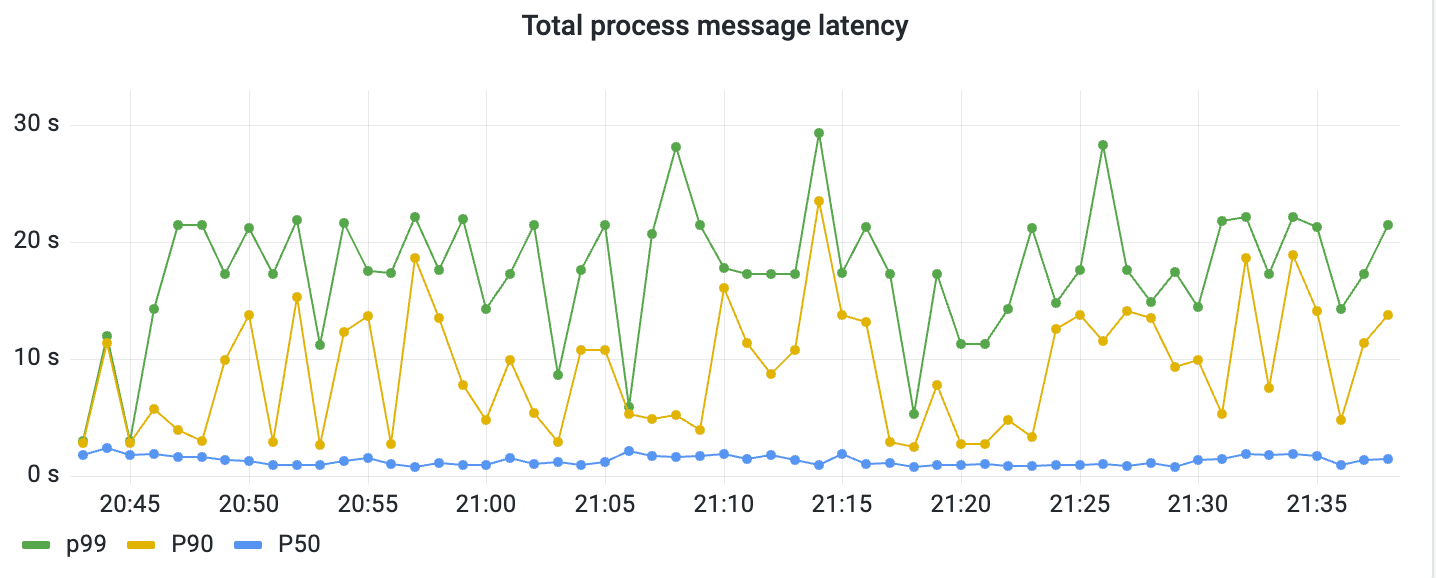
Trying to overcome the challenges from our initial approach and to enhance processing efficiency, we implemented buffered channels to govern the spawning of Go routines in a regulated manner. By leveraging buffered channels, which enable us to control the maximum number of requests in a queue waiting for flight, we could initiate new Go routines as soon as queue space became available.
Diverging from the previous method, we no longer wait for an entire batch of requests to complete. Instead, we await the completion of individual requests, facilitating the swift initiation of subsequent requests. This refined approach markedly improved our overall execution time for processing all requests associated with a specific consumer.
var wg sync.WaitGroup
// buffer to control number of concurrent reqs in flight
buffer := make(chan int, 1000)
for i := 0; i < len(pushTokensArray); i++ {
buffer <- 1
pushToken := pushTokensArray[i]
wg.Add(1)
go func(pushToken string) {
defer wg.Done()
// make HTTP2 call for {pushToken, scorecard payload}
<-buffer
}(pushToken)
}
// proceed after all requests are sent.
wg.Wait()Handling APNs high response latency & request timeouts
Following the buffered channel implementation, we were able to successfully make large number of requests to APNs to deliver realtime score updates. However, we noticed that there were requests with long response time from APNs which led to quite a few request timeouts errors. We tried a few approaches to bring down timeouts and latencies from APNs.
Adding HTTP clients connection pool
Apple recommends using HTTP2-based APIs for communication with APNs. HTTP2 clients utilise a single TCP connection to execute multiple requests using independent streams. However, this singular connection also means that the client is tethered to a single APNs host. Consequently, all requests may be routed to a particular server, potentially leading to timeouts.
To address this issue and distribute our traffic across multiple APNs hosts, we experimented with establishing a connection pool of clients. This approach aimed to ensure that connections were made to various APNs hosts using different HTTP2 clients.
randomClient := rand.Intn(len(httpClientPool))
httpClient := httpClientPool[randomClient]
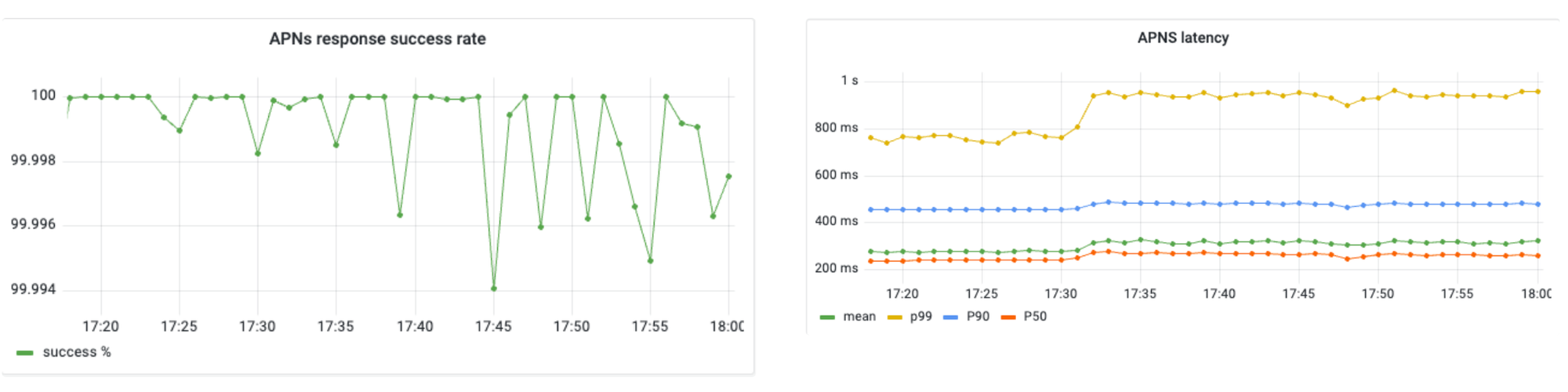
// make request using this httpClient. Despite significant improvements in reducing latencies to less than 2 seconds for P99, we found ourselves still grappling with persistent HTTP timeout errors. We wanted to uncover the root cause and started debugging.
Tackling HTTP Timeouts
Employing httptrace, we monitored the connections to discern the APNs host IPs our backend clients were accessing. To our surprise, a notable portion of HTTP clients consistently gravitated towards a singular APNs host IP. Remarkably, all HTTP/2 clients within a particular backend server converged on this single APNs host IP.
This observation contradicted our expectations for traffic distribution among multiple clients in the connection pool. Upon further reading into how DNS caching works in GKE infrastructure, we attributed this behavior to Kube-DNS caching, which had a TTL (Time to Live) of a few seconds. Consequently, the majority of APNs requests made via Go routines at a particular seconds interval were resolved to the same IP.
One potential solution to address this issue is leveraging uncached DNS, which delivers fresh responses for every query. While promising improved distribution of APNs host IPs among HTTP/2 clients, there are broader unwanted implications. Implementing uncached DNS would inevitably impact all other services operating within our infrastructure.
Rebalancing different APNS host IPs in connection pool
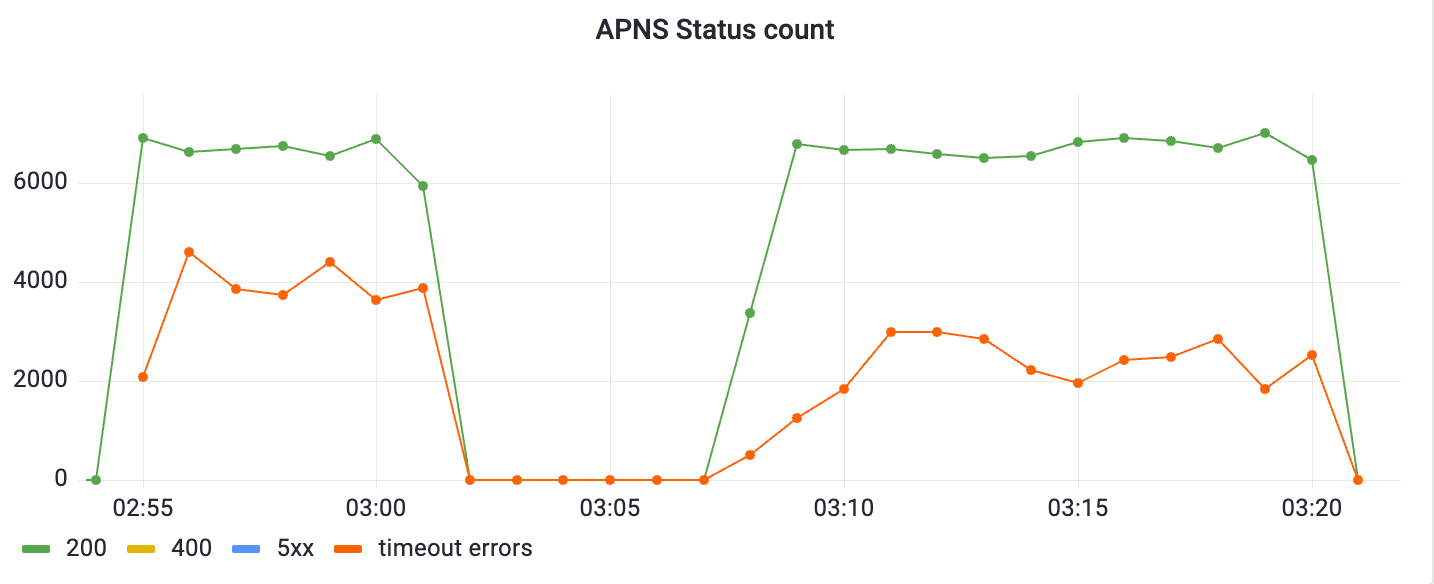
To achieve more efficient distribution of host IPs without modifying Kube-DNS caching, we devised a strategy to prevent the simultaneous opening of a large number of connections. Instead, we gradually exposed connections from the pool over a span of five minutes, allowing only a few connections to be opened initially. This incremental approach ensured that DNS provided different IPs, leading to a more balanced distribution of IPs among the clients in the connection pool.
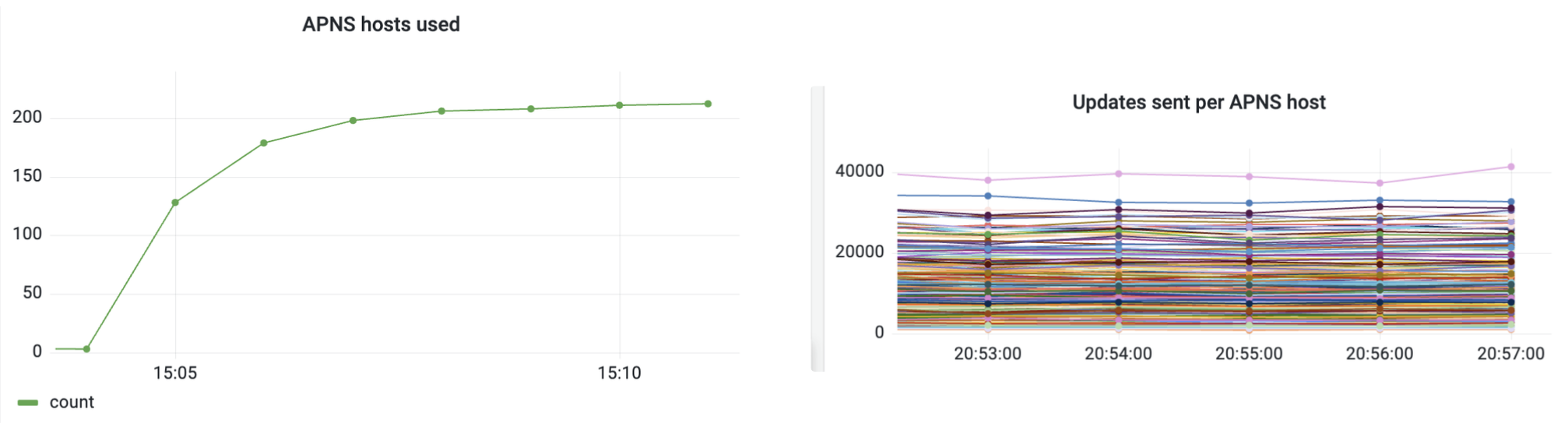
As we can see in above graphic, there were many hosts actively receiving updates. We observed much better diversification of traffic among various APNs hosts and able to minimise aggregated timeout errors as much as possible to 0.003% over the entire duration of the live event.
Summary
Throughout our journey, we've continually fine-tuned our servers, implementing incremental improvements to enhance performance and reliability. From regulating Go routines concurrency to refining our HTTP2 connection pools and implementing a gradual connection start mechanism, we've made significant strides in reducing timeout errors and overall latencies.
However, it's crucial to recognise that achieving zero timeouts while operating humongous scale remains an ongoing challenge. Factors such as server load at APNs and network latency are inherent in real-time communication and cannot be overlooked.
Want to work on problems like these that touch millions of real customers in India? Check out our job openings and drop us a line!