Tuning Go Garbage Collection

We talk about adventures in designing a cost effective "view history" state manager for a customer base of hundreds of millions of customers while keeping our costs under control. Specifically, how our Go GC was eating our lunch!
The Feature
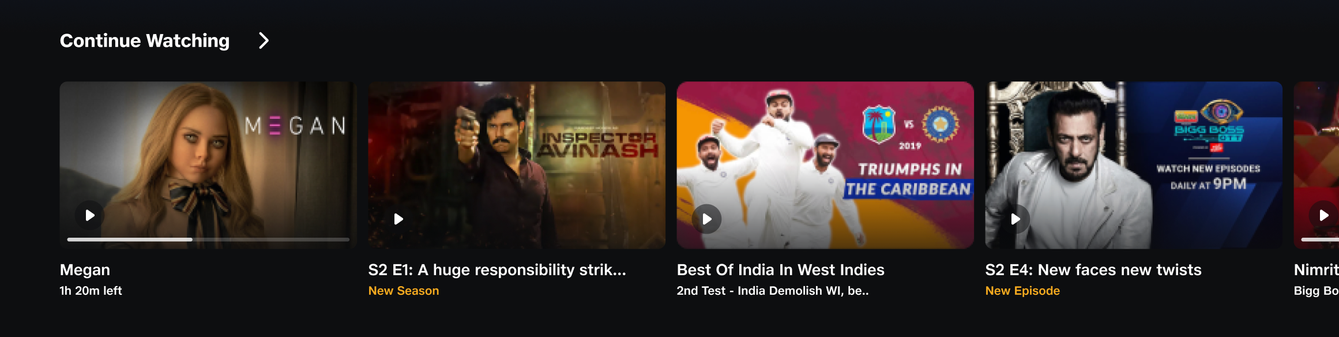
The "Continue Watching (CW)" feature is likely the most common and impactful capability in a digital entertainment platform. This feature ensures that customers can easily pick up where they left off, without expending energy to re-discover their favourite content.
The feature capability consists of the following
- Quick Resume : Remember last watched content position, to resume
- New Episodes / Seasons : Remind me when something I was watching has published new content
On the product, it looks something like this 👇
The Problem Statement
Building a service which keeps track of what our users are watching at scale of hundreds of millions of active users is a challenging feat. At the same time, we can't overlook the challenges that sometimes threaten this experience.
In this blog, we discuss the challenge we faced while pre-populating new episodes and new seasons at scale while keeping cost under control.
Architecture
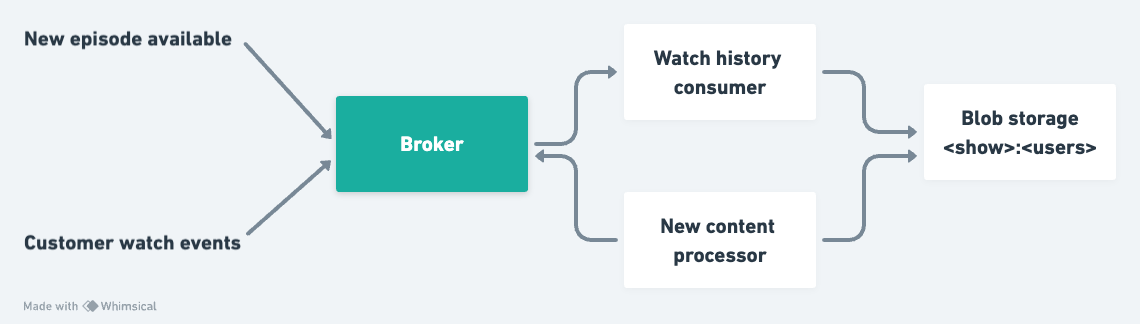
In order to generate a Continue Watching tray for each customer, we track their watch journey via events. When we detect that the latest episode or latest season of a show has been completely watched by a customer, we store this information in a blob storage against the show.
Once we identify that a new episode or a new season of a show has been released, the “new content processor” starts spawning background workers into its own processes.
This is then bundled into packets and produced back to our broker signalling to pre-populate customers continue watching tray.
Challenges
Popular shows have massive fan following where millions of customers tune in every single day to watch newly released episodes. How do you efficiently update the CW tray state of viewers of the show, whittled down to the customers that had already watched all the previously published shows?
Damned if you do ..
Processing the data for such shows added a lot of pressure on the single worker system since it needed to keep track of files it has processed and customers it has notified. With this massive data in place, we realised that we needed to keep scaling vertically. This also posed another challenge where if the worker fails, we had to handle re-processing of all the files and keep track of multiple checkpoints allowing next retry to start from the last processed checkpoint.
Damned if you don't
Scaling horizontally also had its own challenges as the data needed to be partitioned and multiple workers needed to claim the partition they would process. This introduced another layer of complexity where a master would need to keep track of workers and files processed by them and their respective failures to retry them.
Complicating Simplicity
Our first approach was to go ahead with a single worker and it seemed alright until Bigg Boss OTT Season 2 launched, which had massive viewership. As the show grew in popularity, we saw failures and errors being reported by the service.
While we were able to consistently serve the content and manage failures by appropriate checkpoints in place, throughput of our service suffered the most. We weren’t able to deliver new episodes in the tray on time which defeated the entire value proposition of the feature.
We needed a re-think.
Mitigation - Resolve Customer Pain
Our first mitigation strategy was to scale our single worker vertically since we did not want to re-partition the data and get into a reconciliation mess between multiple workers.
But, Wait..
As we enabled vertical scaling, our monitoring system started to alert us about the CPU & memory usage. The service would scale vertically consuming around ~70 cores and memory would spike to ~5 GB during the processing phase. The illustration below shows the typical spikes we saw
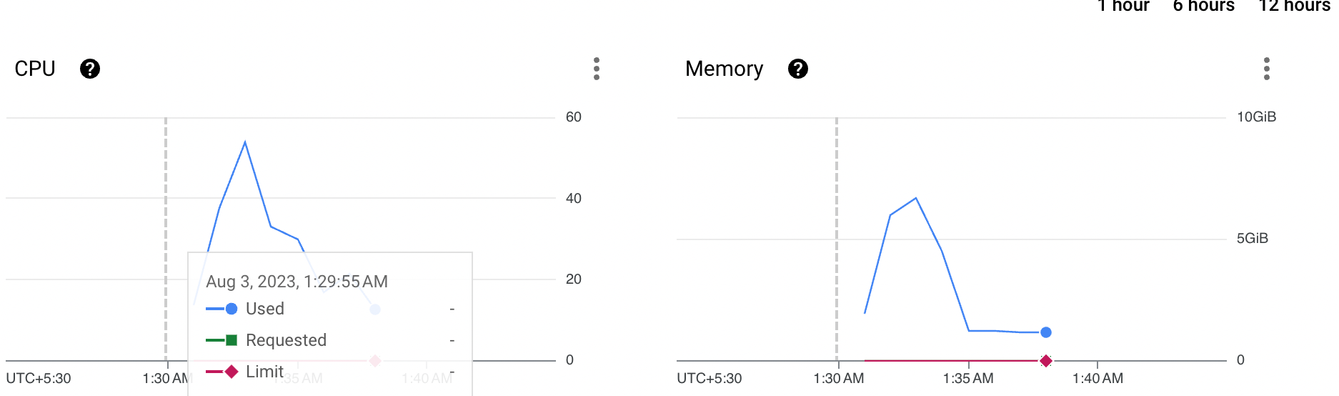
Our first theory was that the heavy I/O done between the service and GCS caused spikes in the CPU and put strain on the memory. The first instinct was to batch the request! Simple and elegant, isn’t it? We tuned our I/Os by batching the requests to GCS and then processing the content within our memory buffers.
We saw some gains, but not significant enough to call this “Done”.
At this point, we started browsing the Go documentation, to deep-dive into the internals of various data structures we used in our worker until we stumbled upon Go’s garbage collector guide to discover this nugget of gold.
”At a high level, GOGC determines the trade-off between GC CPU and memory. It works by determining the target heap size after each GC cycle, a target value for the total heap size in the next cycle. The GC's goal is to finish a collection cycle before the total heap size exceeds the target heap size. Total heap size is defined as the live heap size at the end of the previous cycle, plus any new heap memory allocated by the application since the previous cycle. Meanwhile, target heap memory is defined as:“
Target heap memory = Live heap + (Live heap + GC roots) * GOGC / 100We ran an initial simulation by enabling the GO profiler and viola, we found the culprit!
Salvation In Garbage?
Go was running its GC too frequently which was spiking our CPU resulting in poor performance. We started tuning the GOGC percentage value with different values and kept running the profiler to find a sweet spot that suited our use case.
Once we finalised this value that worked for us, the CPU usage reduced to more than 90% and the memory usage came down by 70-80 % which was a very significant improvement and saved us a lot of cost as well!
Summary
We debate on adding more complexity to our architecure, as new use-cases abound - but for now, things are holding up well, with this new found headroom.
It was an interesting journey for us, where perhaps scaling horizontally seemed like an obvious choice, but our desire to to not over-engineer, and stay rooted in fundamentals, pushed us to look at why we had such high resource usage. In the end, we were able to stay with our current solve while creating a big dent in utilisation on the way. Win Win!
Want to solve interesting problems with us? We’re hiring! Check out open roles at JioCinema Engineering Jobs.